For close to two years now I’ve been blogging about “algorithmic culture” — the use of computational processes to sort, classify, and hierarchize people, places, objects, and ideas. Since I began there’s been something of a blossoming of work on the topic, including a recent special issue of the journal Theory, Culture and Society on codes and codings (see, in particular, the pieces by Amoore on derivatives trading and Cheney-Lippold on algorithmic identity). There’s also some excellent work developing around the idea of “algorithmic literacies,” most notably by Tarleton Gillespie and Cathy Davidson. Tarleton’s recent piece here on Culture Digitally, “Can an Algorithm Be Wrong?” is a major touchstone as well. Needless to say, I’m pleased to have found some fellow travelers.
One of the things that strikes me about so much of the work on algorithmic culture, however rigorous and inspiring it may be, is the extent to which the word algorithm tends to go undefined. It is as if the meaning of the word were plainly apparent: it’s just procedural math, right, mostly statistical in nature and focused on large data sets? Well, sure it is, but to leave the word algorithm at that is to resign ourselves to living with a mystified abstraction. I’m not willing to do that. To understand what algorithms do to culture, and the emerging culture of algorithms, it makes sense to spend some time figuring out what an algorithm is.
Even before getting into semantics, however, it’s worth thinking about just how prevalent the word algorithm is. Why even bother if it’s just some odd term circulating on the fringes of language? What’s interesting about algorithm is that, until about 1960 or so, it was exactly that type of word. Here’s a frame grab from a search I ran recently on the Google Books Ngram Viewer, which allows you to chart the frequency of word usage in the data giant’s books database.
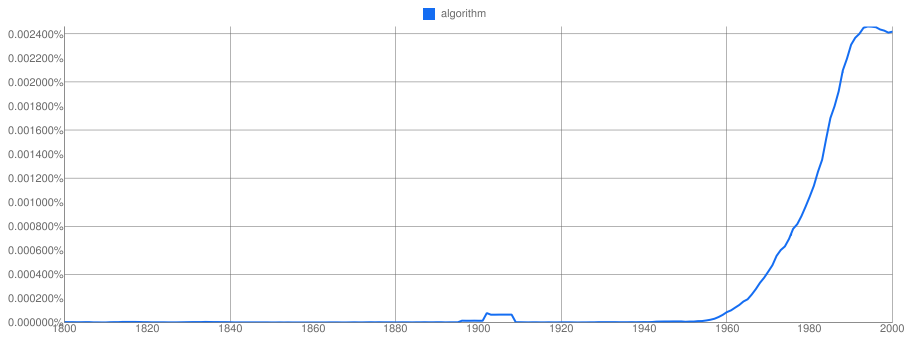
(Yes, I realize the irony in using the tools of algorithmic culture to study algorithmic culture. We are always hopelessly complicit.)
What does this graph tell us? First, algorithm remains a fairly specialized word, even to this day. At its peak (circa 1995 or so) its frequency was just a notch over 0.0024%; compare that to the word the, which accounts for about 5% of all English language words appearing in the Google Books database. More intriguing to me, though, is the fact that the word algorithm almost doesn’t register at all until about 1900, and that it’s a word whose stock has clearly been on the rise ever since 1960. Indeed, the sharp pitch of the curve since then is striking, suggesting its circulation well beyond the somewhat insular confines of mathematics.
Should we assume that the word algorithm is new, then? Not at all. It is, in fact, a fairly old word, derived from the name of the 9th century Persian mathematician al-Khwārizmī, who developed some of the first principles of algebra. Even more intriguing to me, though, is the fact that the word algorithm was not, until about 1960, the only form of the word in use. Before then one could also speak of an algorism, with an “s” instead of a “th” in the middle.

Based on the numbers, algorism has never achieved particularly wide circulation, although its fortunes did start to rise around 1900. Interestingly, it reaches its peak usage (as determined by Google) long about 1960, which is to say right around the same time algorithm starts to achieve broader usage. Here’s what the two terms look like when charted together:

Where does all this leave us, then? Before even attempting to broach the issue of semantics, or the meaning of the word algorithm, we first have to untangle a series of historical knots.
- Why are there two forms of the “same” word?
- Why does usage of algorithm take off around 1960?
- Why does algorism fade after 1960, following a modest but steady 60 year rise?
I have answers to each of these questions, but the history’s so dense that it’s probably not best to share it in short form here on the blog. (I give talks on the subject, however, and the material all will eventually appear in the book.) For now, suffice it to say that any consideration of algorithms or algorithmic culture ought to begin not from the myopia of the present day but instead from the vantage point of history.
Indeed, it may be that the question, “what is an algorithm?” is the wrong one to ask — or, at least, the wrong one to ask, first. Through what historical twists and turns did we arrive at today’s preferred senses of the word algorithm? That seems to me a more pressing and pertinent question, because it compels us to look into the cultural gymnastics by which a word with virtually no cachet has grown into one whose referents increasingly play a decisive role in our lives.